
Jellyfish_'s airshot Mar. 23, 2021 in Games, Videos
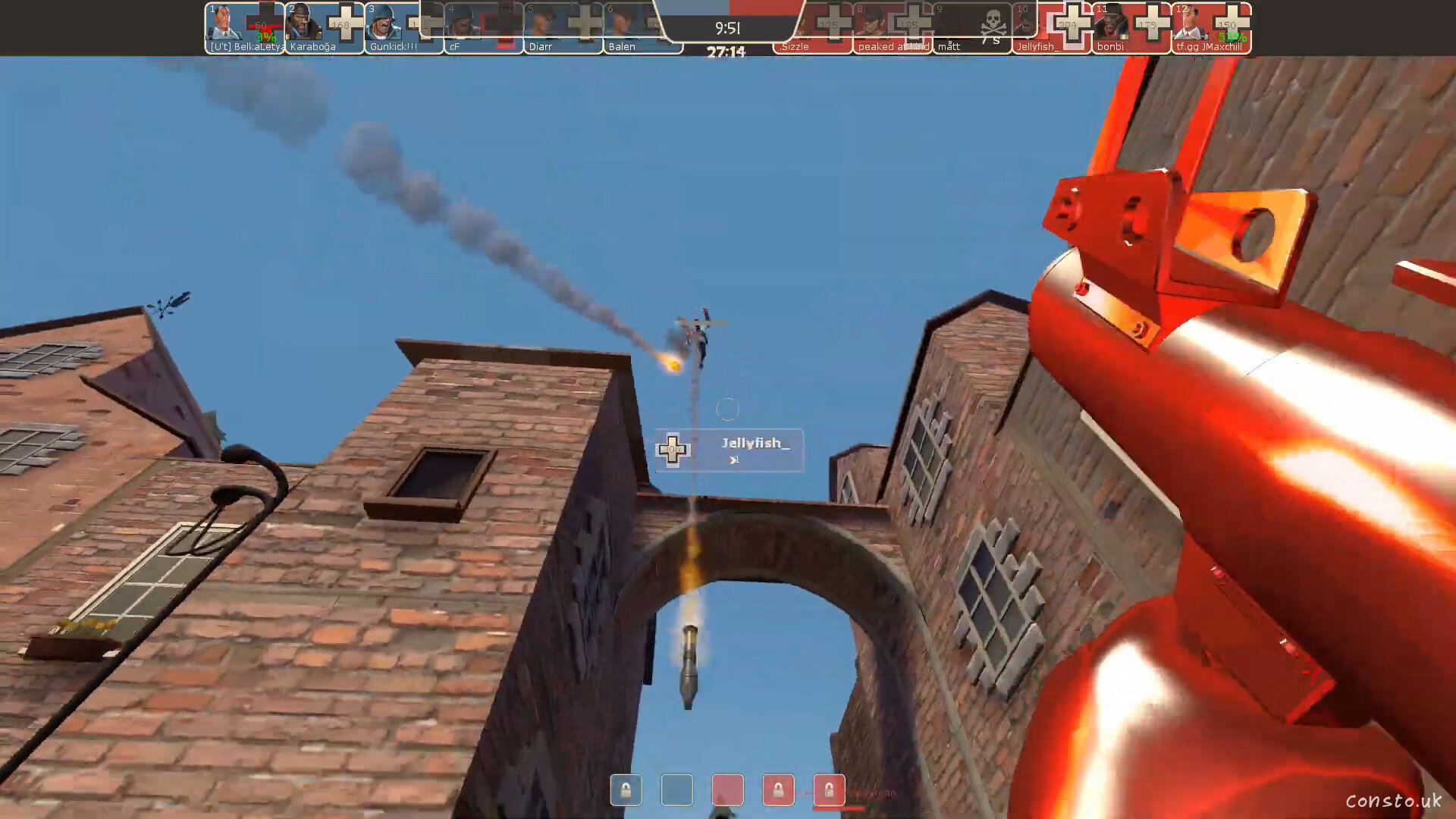 Jellyfish_'s airshot Jellyfish_'s airshot
Jellyfish_'s airshot Jellyfish_'s airshot  BathTub Virtual Orchestra - Santa Baby
BathTub Virtual Orchestra - Santa Baby Since lockdown, we’ve been unable to practise in person so we’ve been keeping sharp online! In this video we’ve individually recorded each part of Santa Baby, and re-assembled them into this video.
About a year ago I purchased myself a brand-new Acer Triton 500 gaming laptop. It has overall been a great purchase, and I especially love the 144Hz IPS display paired with a powerful graphics card. However, in the time I have had it, I have twice had the Killer WiFi and Bluetooth stop working with a Code 10 error message. Fortunately, there is a quick an easy fix! Restarting and reinstalling drivers doesn’t work; you just need to reset your BIOS.
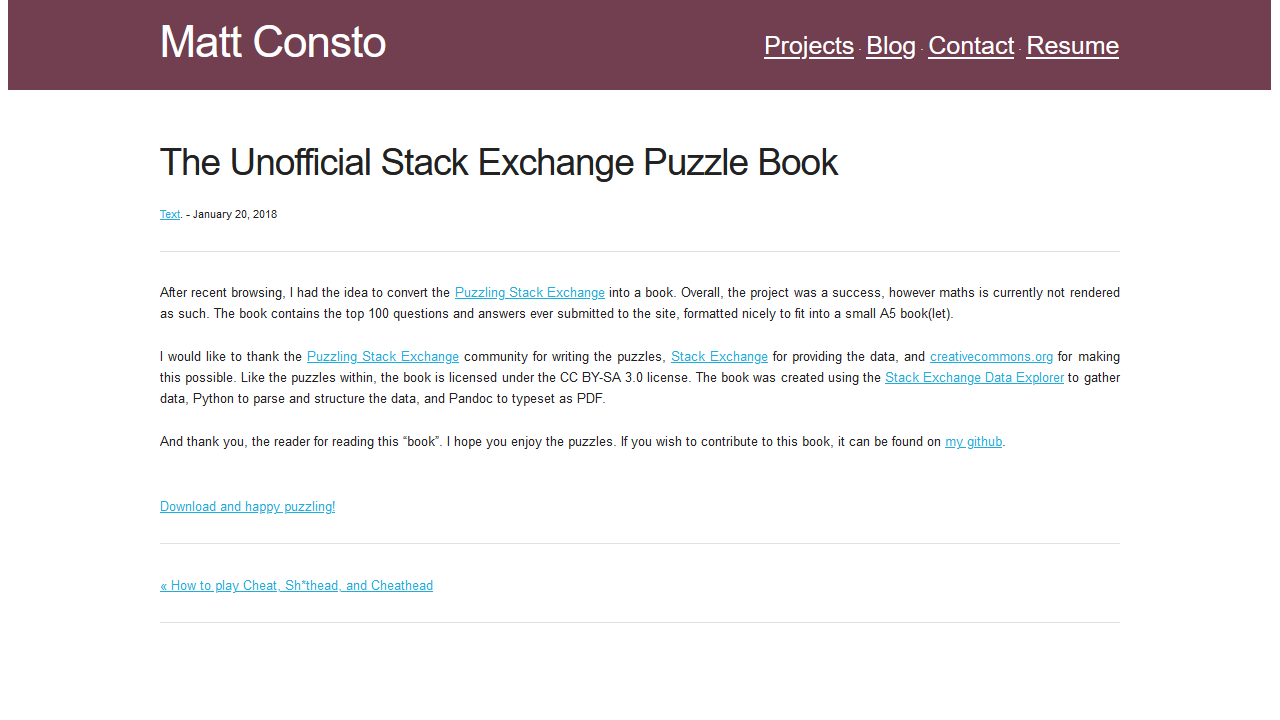
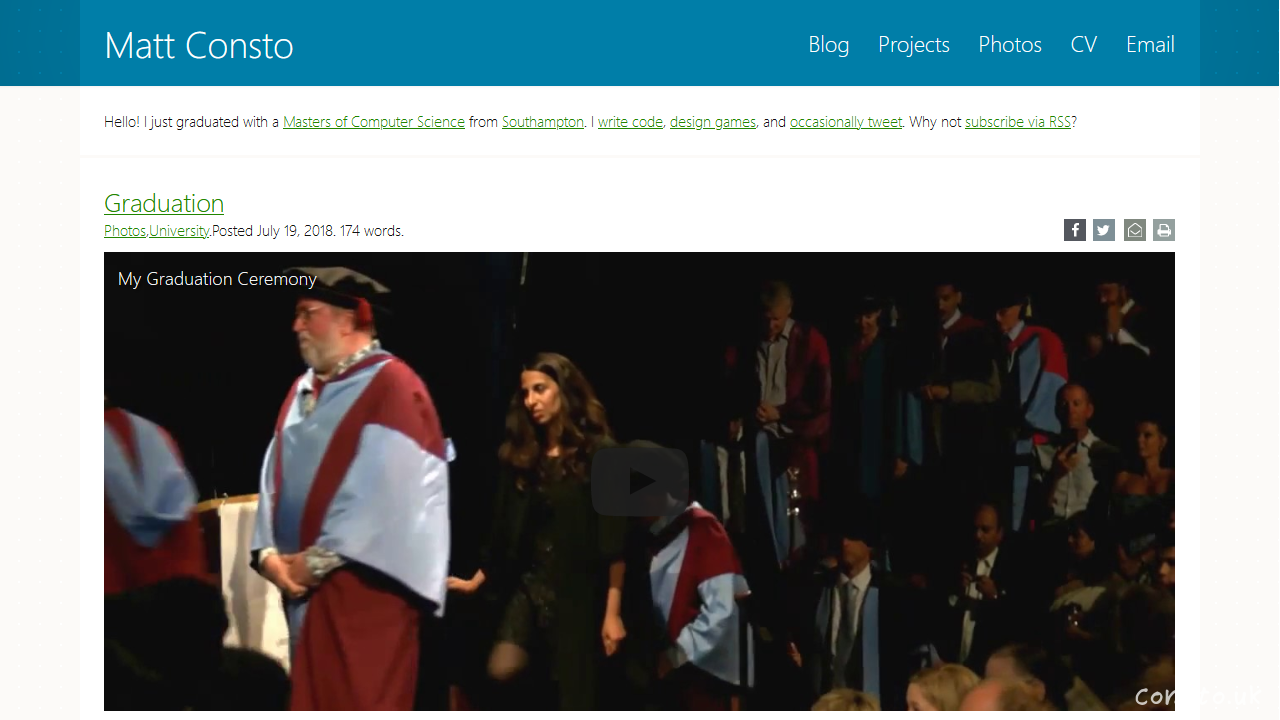
Using Internet Archive’s Wayback Machine, here are screenshots of my blog from 2018, 2019, and 2020. Can you believe it’s August?
In the last few days, I’ve been busy re-theming this site, and finally finishing many of my existing projects.
I’ve added lots of missing features, improved the user-experience, added some difficulty options, significantly increased performance, added new tools, improved the visual appearance, added mouse/touch support where applicable, and even made most things (including this blog) work in browsers as old as Internet Explorer 11.
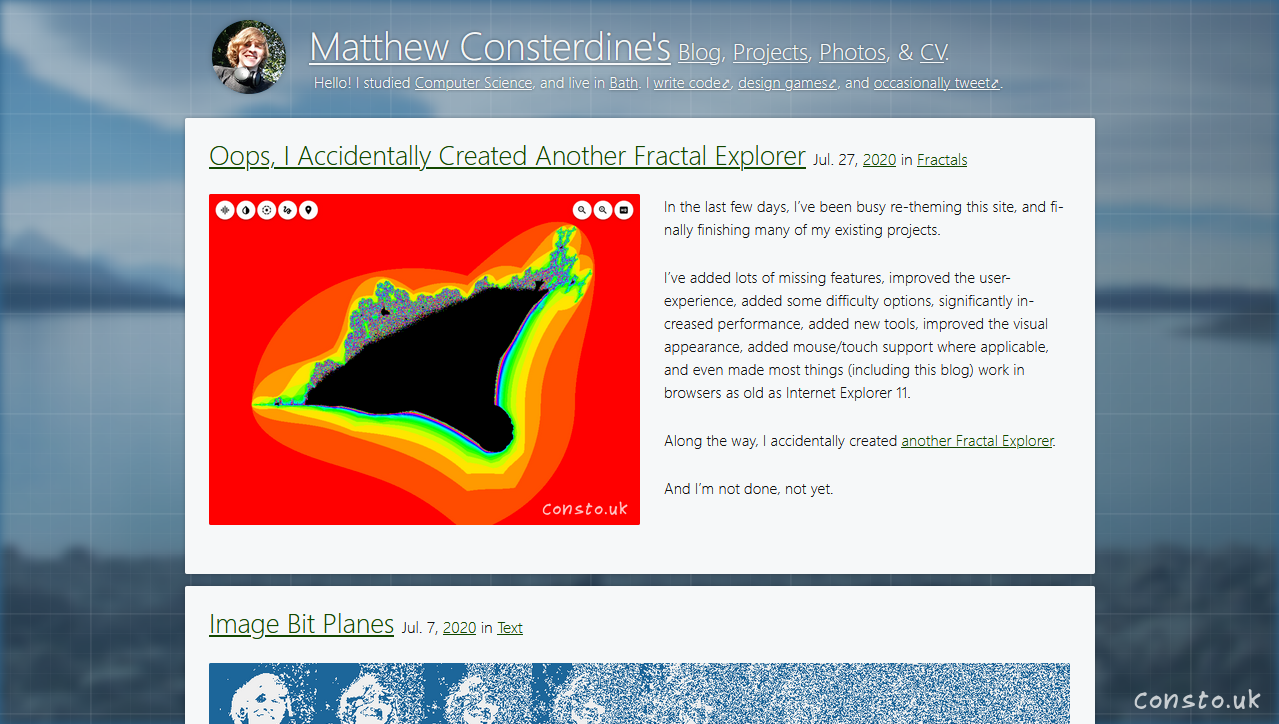
Along the way, I accidentally created another Fractal Explorer.
And I’m not done, not yet.

 BathTub Virtual Orchestra - Take On Me
BathTub Virtual Orchestra - Take On Me Since lockdown, we’ve been unable to practise in person so we’ve been keeping sharp online! In this video we’ve individually recorded each part of A-ha - Take On Me, and re-assembled them into this video.
 BathTub Virtual Orchestra - Cars
BathTub Virtual Orchestra - Cars Since lockdown, we’ve been unable to practise in person so we’ve been keeping sharp online! In this video we’ve individually recorded each part of Gary Numan - Cars, and re-assembled them into this video.
I made a FireFox extension called TabTool mainly for me, but also for anyone else who wants to give it a try.
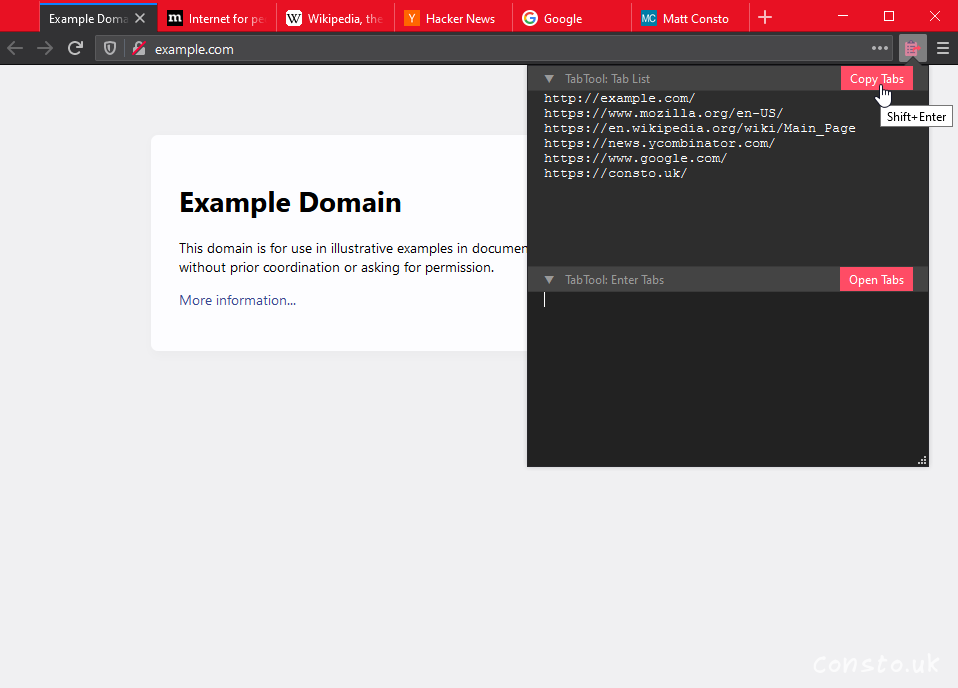
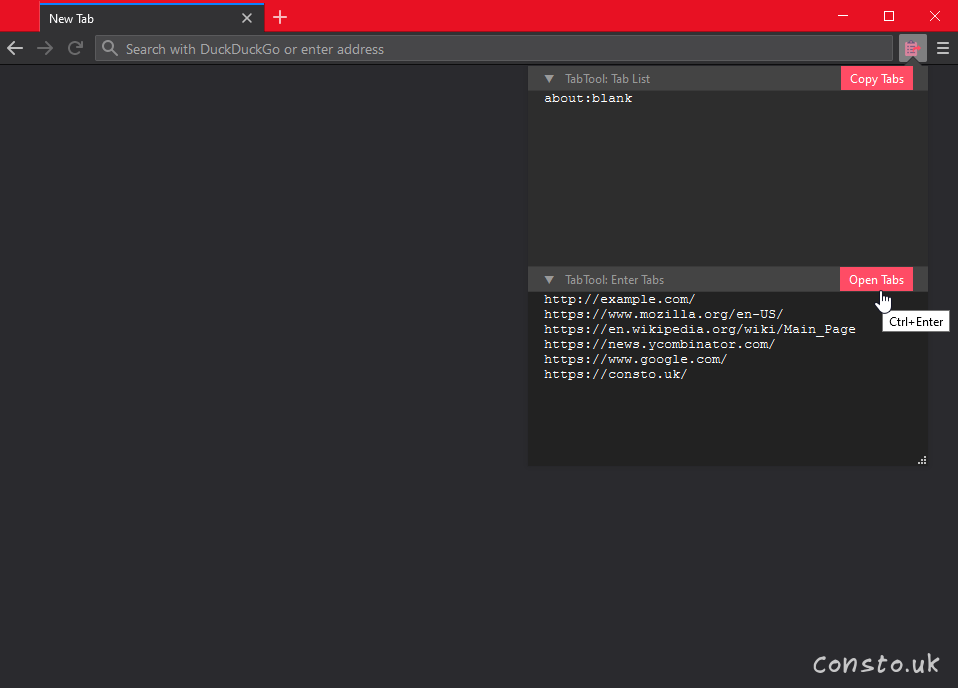
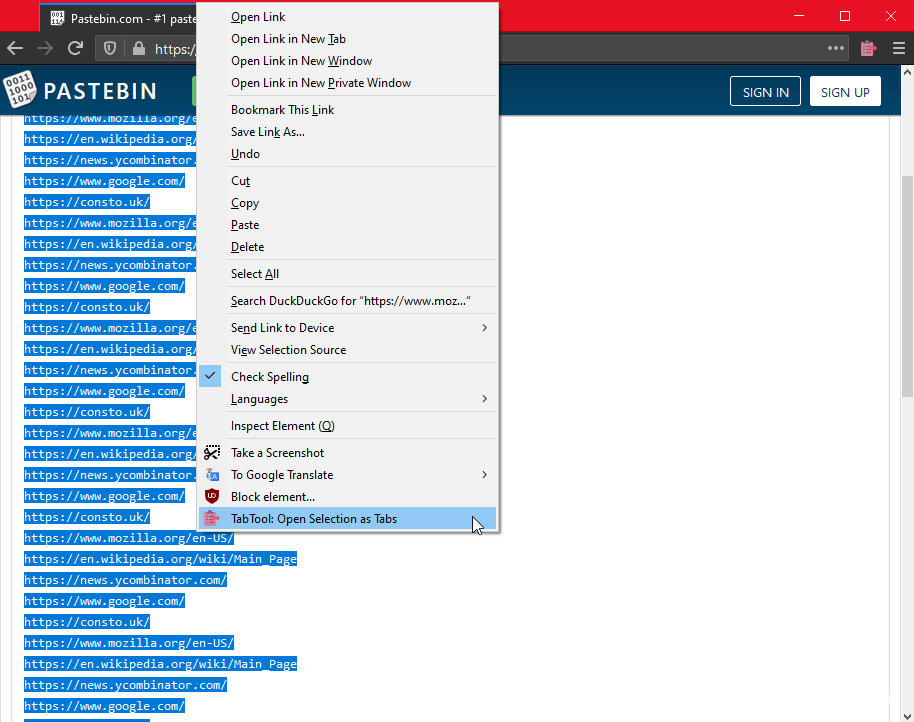
A minimal Firefox browser extension that lets you easily copy, manipulate, and open list of URLs. Supports light and dark!
